



RAG(ラグ)とは、ChatGPTやGeminiなどの一般的な生成AIに、社内の独自データを追加利用できる仕組みのこと。本記事ではRAGの仕組みやできること、回答精度を高める方法などについて、実際の検証結果もふまえてわかりやすく解説します。
RAG(ラグ)とは、大規模言語モデル(LLM)と、社内情報などの独自データを組み合わせて回答を生成する手法です。「Retrieval(検索)- Augmented(拡張)- Generation(生成)」の略であり、日本語では「検索拡張生成」とも呼ばれ、生成AIの活用手法の一つに位置づけられます。
あらかじめLLMにすべての情報を学習させるのではなく、社内マニュアルや規程、業務文書などを外部データベースとして保持し、必要に応じて検索・参照しながら回答を生成する点が特徴です。これにより、LLM単体では扱えない独自情報を活用した回答が可能になります。
RAGとChatGPTやGeminiなどの一般的な生成AIの大きな違いは、「利用できるデータの範囲」にあります。一般的な生成AIは、主にインターネット上の公開情報や学習済みデータをもとに回答を生成します。一方、RAGでは、インターネット上には存在しない、または公開していない社内規定・業務資料・顧客情報などの独自データを追加で参照できる点が大きな特徴です。
従来の生成AI活用には、以下のような課題がありました。
RAGでは、ナレッジを外部データとして“後付け”で参照するため、これらの課題を大幅に軽減できます。また、RAGはLLMのアップデートや変更に対する耐性が高い点も特長です。
LLMを「頭脳」、RAGを「参考書」に例えると、新しいLLMが登場した場合でも「頭脳」を入れ替えるだけで対応が可能です。システム全体を作り直す必要がないため、技術進化の速いAI分野においても、長期的に運用しやすい仕組みといえます。
RAGは主にビジネスシーン、特に社内問い合わせ対応や専門文書の作成支援といった社内情報を活用するシーンで導入が進んでいます。以下、RAGの活用例について具体的なユースケースを紹介します。
RAGに業務マニュアルや各種規程、FAQなどを読み込ませることで、自社専用の問い合わせ対応AIを構築できます。
想定質問と回答を事前に用意しなくても、データベースから該当情報を検索し、その内容をもとに回答を生成するため、従来のFAQシステムよりも柔軟で詳細な対応が可能です。社内ヘルプデスクだけでなく、カスタマーサポートへの応用も進んでいます。
NotionやLarkなどのグループウェア、BoxやOneDriveといったオンラインストレージと連携することで、散在しがちな社内情報を横断的に検索できます。
過去の会議資料や成功事例、商談記録などに素早くアクセスできるため、提案資料の作成やアイデアのブラッシュアップ、属人化の解消にもつながります。
市場データ、業界レポート、ニュース記事、顧客アンケートなど、複数のデータソースをRAGに格納することで、必要な情報を検索し、要点を整理した形でアウトプットできます。
自社で収集した独自データを組み合わせれば、市場動向レポートの作成や競合製品の比較・評価など、分析業務の効率化と高度化が可能です。
RAGの具体的な導入メリットとして、以下のようなものが挙げられます。
大規模言語モデル(LLM)は、主にインターネット上で公開されている情報をもとに回答を生成します。そのため、社内規程や業務マニュアル、過去の商談資料といった非公開の独自情報を直接参照することはできません。
一方、RAGでは、社内文書や業務マニュアルなどをナレッジベースとして利用できるため、自社固有の情報に基づいた回答生成が可能です。専門性が高く、正確性が求められる業務領域においても、実務に即した情報提供を行える点が大きなメリットです。
LLM単体で回答精度を高めようとする場合、モデルの選定やプロンプトの調整など、試行錯誤が必要になります。しかし、参照する情報が非常に広範であるため、「なぜその回答になったのか」「どこを改善すればよいのか」といった因果関係が分かりにくく、精度向上に時間がかかるケースも少なくありません。
RAGでは、回答精度はLLMそのものよりも、「どのデータを、どのように検索・参照させるか」に大きく依存します。利用するデータ範囲が限定されている分、改善ポイントを特定しやすく、ナレッジの整理や検索条件の調整によって、比較的コントロールしやすい形で精度を高められる点が特徴です。
RAGで利用するナレッジは、あらかじめ用意したデータベースに限定されるため、一般的なLLMのように入力内容が学習に使われることはありません。更に、社内サーバーやクローズドな環境にRAGのデータベースを構築すれば、格納した情報が社外に流出するリスクも抑えられます。
そのため、個人情報や機密情報を含むデータであっても、セキュリティを確保した状態でAI活用が可能です。情報漏洩リスクを懸念して生成AIの導入を見送っていた企業にとって、RAGは有力な選択肢となります。
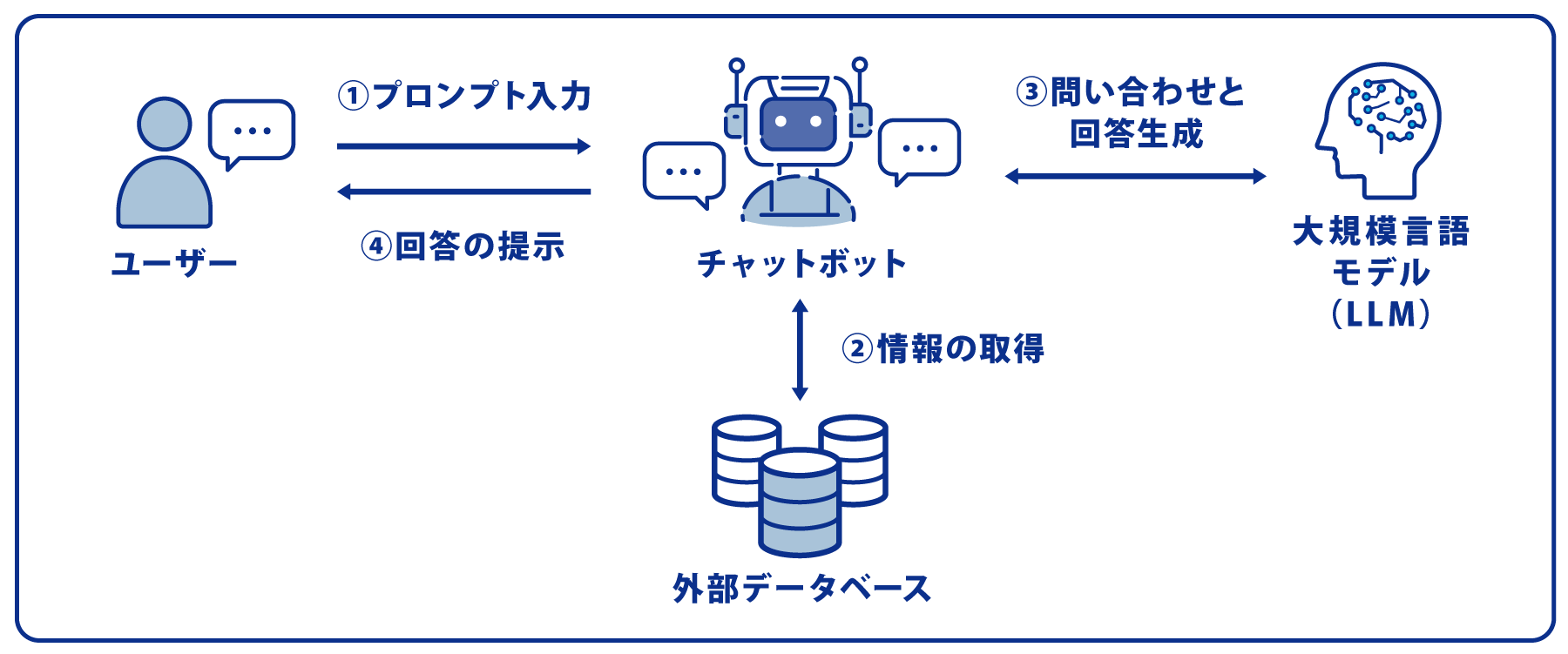
冒頭「RAGとは?」で解説した通り、RAGでは大規模言語モデル(LLM)に加えて、外部データベースを活用して回答を生成します。たとえば、チャットボットでRAGを利用する際は以下の順番で処理が行われます。
まず、外部データベースに独自情報を登録します。多くのRAGシステムはPDFやWordなどの文書ファイルに対応。これらの文書ファイルをRAGシステムにアップロードすると、RAGが「チャンク化(データの塊ごとに保管)」「オーバーラップ(データの塊が一部重なるように調整)」といったデータ処理を行います。
入力されたプロンプト(質問)に対して、チャットボットはプロンプト処理技術を使って、適切に解釈します。
チャットボットで処理されたプロンプト情報をもとに、外部データベースから該当する情報を検索して抽出。「RAGのよくある失敗と回答精度を高める方法」で後述する「ベクトル検索」などの検索方法を用いて実行します。
外部データベースから抽出した独自情報をLLMに送信し、回答の生成を依頼します。LLMを経由することで、質問意図を汲んだ回答を生成できるようになります。
チャットボットはLLMとやり取りをして得た回答をユーザーに応答します。この際、RAGシステムによっては、参照ファイル名の表示や、参照箇所のテキスト表示が可能です。
RAGの活用にあたって、最も気になるのは回答精度。どれだけの回答精度が実現できるのか、アスピック編集部が実際に検証してみました。
今回の検証は、以下の環境のもとで行いました。
| 利用サービス | RAG機能搭載のノーコードLLMアプリ開発プラットフォーム「Dify」 |
|---|---|
| LLM |
|
| 格納データ | 某独立行政法人が公開している 職員給与規程、就業規則などの各種規程集(文書、表) |
なお、今回データベースに格納したのは10ファイル程度。一般的に、ファイル数が増えるほど適切なドキュメントを見つけるのが難しくなるため、回答精度が低下する傾向があります。
多くのデータ/ファイルを扱う必要がある場合は、たとえば、給与規定は「給与規程チャネル」、就業規則は「就業規則チャネル」といったようにファイルの格納場所を分けることで、回答精度の維持が見込めます。ファイル数の問題に加えて、回答精度にはデータの質も影響します(後述)。
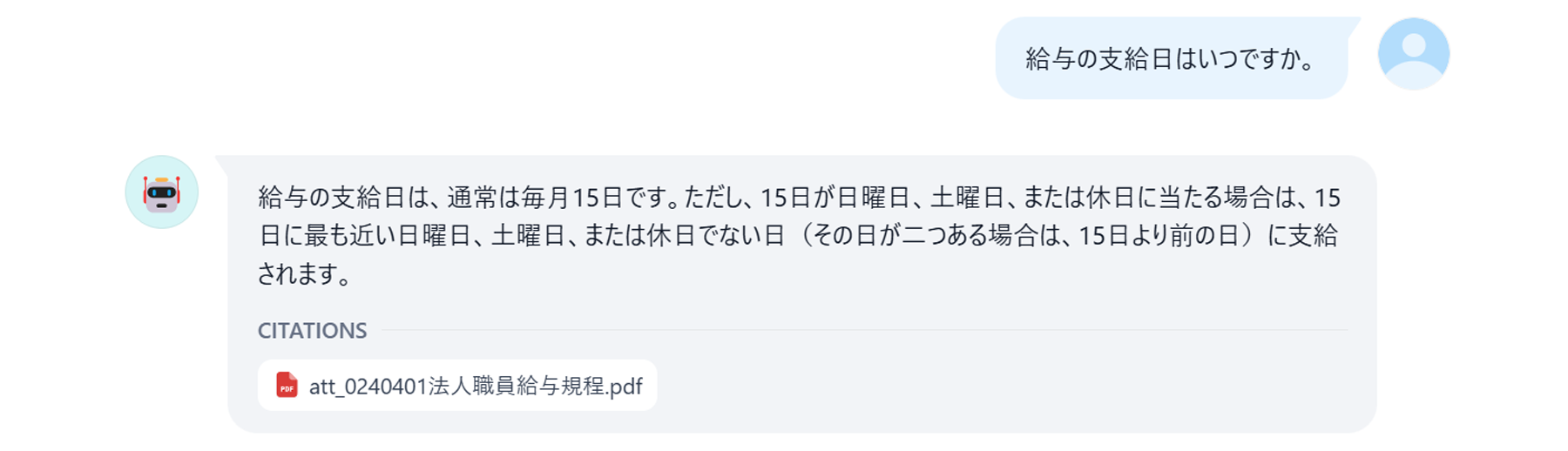
100件の質問をしたところ、正答率は約70%でした。ただし、文書にどのように記載されているかによって回答精度の違いが見られます。文章が羅列されて書かれている内容や、簡単な表(2列の表)で記載されている内容には関しては70%以上の正答率がありました。一方で、複雑な表(3列以上の表)の場合は正答率が30%以下でした。
回答精度が低い場合には技術的な改善のほかに、プロンプトの工夫やデータの加工といった対策が有効です。次項で解説する対策を行うことで、実際のRAG導入時にはより精度を高められる可能性があります。
RAGは適切に構築すれば高精度で動作しますが、設定を誤ると「正しく検索されない」「誤回答が多い」といった課題が起こります。
ここでは、企業導入で特に多い3つの失敗と改善策を解説します。どのような失敗があり、それぞれどのような方法を使えば回答精度を高められるのか、実際の検証結果をもとにご紹介します。
よくある失敗の一つが、不正確・曖昧なプロンプトによる不具合です。
プロンプトとは、生成AIに対してユーザーが行う質問や指示のこと。プロンプトが抽象的だったり、前提条件が抜けていたりすると、回答ミスが発生しやすくなります。ミスを防ぎ、回答をより正確にするためには、以下の4点を可能な限り詳細に伝えることが重要です。
| 1.役割 | AIに求める役割を明確にする。 (例:優秀なチャットボット、プロの問い合わせ担当者) |
|---|---|
| 2.依頼事項 | どんなことをしてほしいか具体的に指示をする。 (例:ユーザーが特定のキーワードや質問を入力した場合、それに関連する内容を的確でわかりやすいテキスト形式で提供してほしい、など) |
| 3.回答例 | 求める回答の仕方、回答例を事前に与える。 (例:Q.ハルシネーションとはなんですか? A. AIが架空の情報や誤った情報を回答してしまうこと) |
| 4.ルール | 生成AIに守ってほしいルールを伝える。 (例:必ずRAGに格納された情報をベースに回答してください) |
RAGはLLMではなく、検索(Retrieval)の精度に依存します。そのため参照元となるデータの質が低いと、どんなに優れたプロンプトであったとしても、回答の精度が低下します。
RAGの参照元となるデータが原因で失敗が起きやすくなるのは、特に以下の場合です。
最新のLLMでも、複雑な表については理解できない場合が多々あります。アスピック編集部の検証でも、2列までの簡易的な表に関する情報は回答できましたが、3〜4列の表や、セルが結合されている表に関しては、うまく回答することができませんでした。
こういった場合の対策として、データの加工が最優先です。たとえば、表データはCSVなど文脈情報を保持した形式に変換する、不要なフッターや広告などのノイズは除去する、重複した情報は削除するなど、データクレンジングを徹底しましょう。初期段階におけるデータの前処理が、長期的な精度向上につながります。
データとプロンプトが正確でも、検索設定が合っていなければ、LLMは正しい情報源にたどり着けずに質の低い回答を生成してしまいます。データやユーザーの特性に合わせて、複数の検索手法やリランク処理を適切に活用しましょう。
検索手法とは、RAGの中からユーザーの質問に関係するチャンク(データの塊)を抜き出す際に利用される検索の種類のことです。主として、3つの検索手法があります。
| 全文検索 | 質問のキーワードが含まれている文章を、すべての文書から探し出す検索手法。すべての文書が検索対象となるのがメリットです。意味が明確でない固有名詞を含むキーワードを見分けることも可能です。 |
|---|---|
| ベクトル検索 | ユーザーの質問をベクトル化して、類似度が高い文章を探す検索手法。質問をベクトル化することで数学的な計算に基づいた検索が可能になるため、高速で実行できるというメリットがあります。 |
| ハイブリット検索 | 全文検索とベクトル検索を組み合わせた検索手法。それぞれの検索手法の良い部分は残しつつ、苦手な部分を補い合えるため、より回答精度を上げられます。 |
適切な検索手法を選択・実装することで、関連性の高い情報を効果的に抽出できるようになり、回答精度が向上します。
リランク処理とは、RAGの情報から検索手法を使ってヒットしたチャンクを、より類似度が高いスコア順に並び替える手法です。リランク処理を行うことで、チャンクを適切な順番でランキング付けできるようになるため、より回答精度を高められます。
使われることが多いのが、Cohere社が提供しているリランクモデル。検証の際も同社のリランクモデルを使うことで、より精度の高い回答を出力できました。
最後に、実際にRAGを導入するための主な方法を4つご紹介します。
RAG対応の法人向けChatGPTサービスを利用する方法です。代表例に、株式会社ギブリーの「MANA Studio」や、株式会社エクサウィザーズの「exaBase 生成AI」などがあります。
これらのサービスを利用するメリットは、独自にRAG環境を構築する手間をかけず、SaaSとして利用できる点です。いずれも利用スタート時点からプロンプトがテンプレート化されているため、プロンプトを準備する負担も軽減されます。
「利用情報をLLMの学習データとして利用しない」「データ処理はすべて日本国内で完結」という仕様が多いため、セキュリティ面やコンプライアンス面でも安心です。
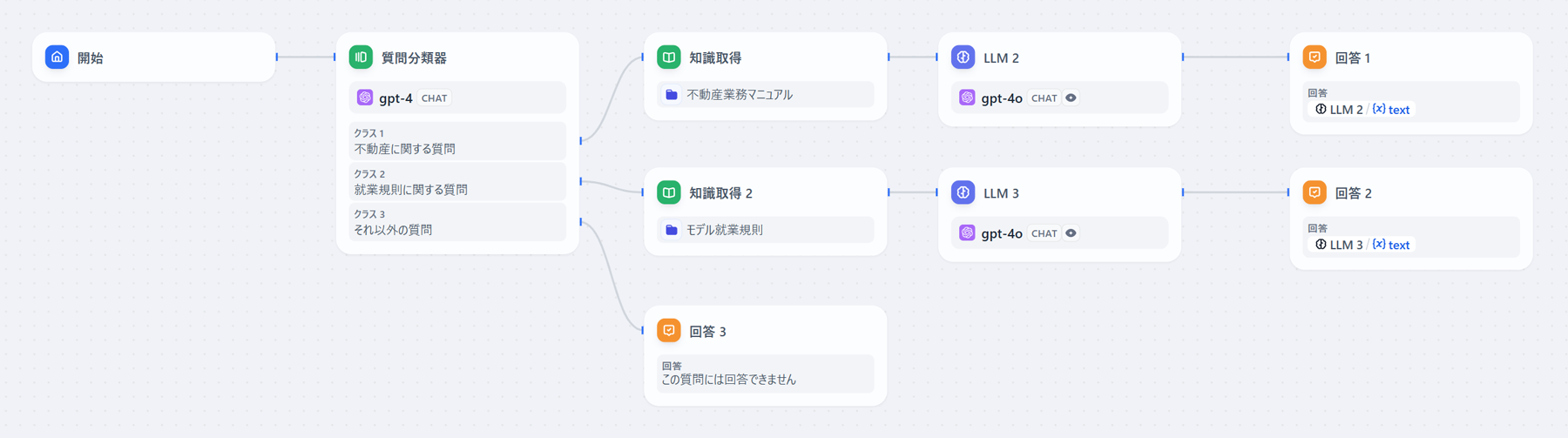
ノーコードLLMアプリ開発プラットフォームを使って、自社で開発を行う方法。代表例として「Dify」や「Coze」などがあります。直感的なGUI操作のみで非エンジニアでもRAG環境を構築できる上、「簡単にLLMのモデルを変更できる」「検索手法やリランク処理・埋込モデルなどを自由にカスタマイズできる」といったメリットも。
チャットボットの処理方法(チャットフロー)に関しても、パーツを組み合わせるだけでイメージ通りに作成可能です。たとえば「Dify」には入力された質問の内容に応じて、AIが質問を振り分けられる「質問分類器」が搭載されています。この機能を使って、質問内容に該当する資料をRAGから読み取り、LLMで回答を生成させる、といったワークフローも簡単に設定できます。
Azure AIサービスやAmazon Bedrockといったサービスには、RAG以外にも、生成AI関連サービスを効率的に開発するための幅広い機能が用意されています。メリットは、LLMノーコード開発ツールに比べて、独自のカスタマイズがしやすいこと。ただし、コーディングやインフラ設定の知見が必要なため、エンジニア向けの方法といえます。
「自社のリソースを割きたくない」「プロの手で環境を構築してほしい」「導入後の検証作業や社内浸透まで伴走してほしい」という場合は、アウトソーシングがおすすめです。
生成AIの精度を上げ、社内資料などの外部データベースに基づいて独自の回答を可能にする「RAG(検索拡張生成)」をご紹介しました。従来の生成AIの弱点である「誤解答(ハルシネーション)」「最新の情報不足」「独自情報の欠如」をカバーし、自社の規定に沿った回答を出力。「社内外からの問い合わせ対応」「社内ナレッジの検索」「市場調査、競合分析」といったビジネスシーンで活用が進んでいます。
RAGの導入方法は、主に以下の4つが挙げられます。
RAGの活用には「独自情報に基づいて回答を生成できる」「回答精度を改善しやすい」「社内情報を安全に利用できる」といったメリットがある一方、プロンプトやデータ、処理方法を適切に設定していなければ、質の低い回答が生成されるケースも。
そのため「導入したいがノウハウがなく不安」「自社の負担を最低限に抑えたい」「独自性の高い要件をクリアしたい」といった場合には、「4.RAG環境構築を依頼する」を検討してみてください。

生成AIでどの業務を自動化できるのか? 問い合わせ対応を中心に7事例を紹介
記事をシェア




アスピックご利用のメールアドレスを入力ください。
パスワード再発行手続きのメールをお送りします。
パスワード再設定依頼の自動メールを送信しました。
メール文のURLより、パスワード再登録のお手続きをお願いします。
ご入力いただいたメールアドレスに誤りがあった場合がございます。
お手数おかけしますが、再度ご入力をお試しください。
ご登録いただいているメールアドレスにダウンロードURLをお送りしています。ご確認ください。
サービスの導入検討状況を教えて下さい。
本資料に含まれる企業(社)よりご案内を差し上げる場合があります。
資料ダウンロード用のURLを「asu-s@bluetone.co.jp」よりメールでお送りしています。
なお、まれに迷惑メールフォルダに入る場合があります。届かない場合は上記アドレスまでご連絡ください。

